Document's Vectorization
Discover how to turn your document to an AI embedding via the Vectorization process.
Introduction
- Rivalz is not only a storage service but also a powerful AI platform that can help you to extract knowledge from your documents.
- The Vectorization process is the process of converting a document into a vector representation. This vector
representation is a numerical representation of the document that can be used by machine learning models to perform
various tasks such as classification, clustering, and similarity search.
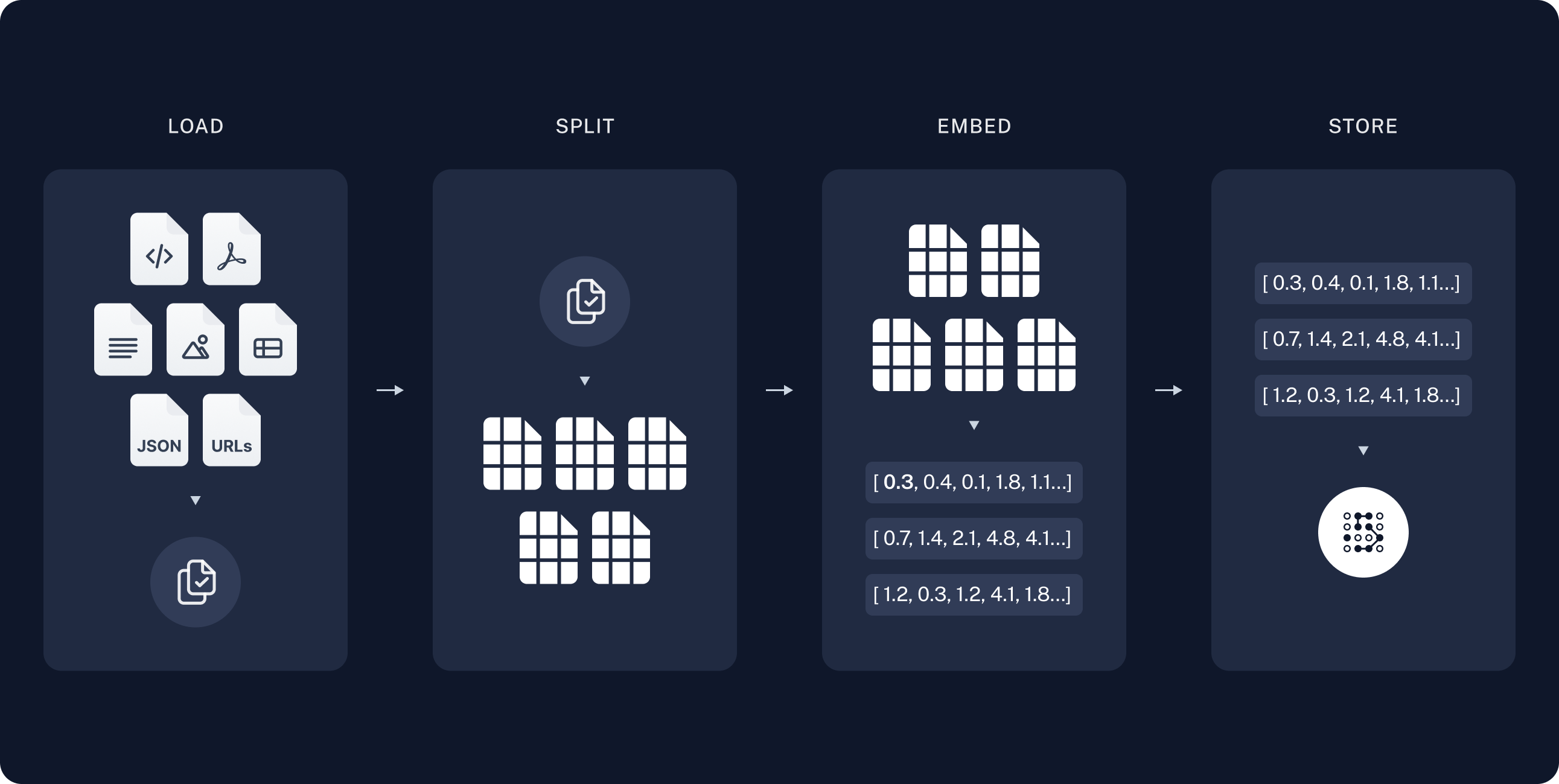
- In Rivalz, we provide a simple and easy-to-use API to vectorize your documents end embed them into an AI model Which create a custom ‘knowledge base’ for your organization.
- For this version we only support PDF documents
Create your first knowledge base
Prerequisites
- Saving vector data is a costly operation, so you need credits to create a knowledge base. Don’t worry! We provide you
with 500 USD free credits when you create an account. Claim your free credits now by visiting
the Rivalz console. And click on the
Create creditbutton. InProfiletab.

- Prepare your document in PDF format.
- Also, you need to have an API secret key to authenticate your request. If you don’t have one, please refer to the Authenticate and secret keys section to get one.
Create a knowledge base
- Knowledge base is a collection of information that the chat agent can use to answer questions and provide assistance to users.
- Use our SDKs to create a knowledge base.
Setup the SDK
- Chose your preferred SDK we now support Python and Node.js.
- Install the SDK using the following command:
- Python
pip install rivalz-client
- Node.js
npm install rivalz-client
Prepare your document
- Prepare your document in PDF format.
- Place your document in the same directory as your script.
Initialize the client
-
Initialize the client with your secret token. You can create
.envfile withSECRET_TOKENvariable and store your secret token in it. Or you can directly pass the secret token to the client. -
For loading the secret token from the
.envfile, you can use thepython-dotenvpackage in Python anddotenvin Node.js. By executingpip install python-dotenvornpm install dotenv- Python
from dotenv import load_dotenv
from rivalz_client.client import RivalzClient
load_dotenv()
# Get the secret token from environment variables
secret_token = os.getenv('SECRET_TOKEN')
if not secret_token:
raise ValueError("SECRET_TOKEN is not set in the environment variables.")
# Initialize the RivalzClient with the secret token
client = RivalzClient(secret_token)
- Node.js
import RivalzClient from 'rivalz-client';
import dotenv from 'dotenv';
dotenv.config();
const rivalzClient = new RivalzClient(process.env.SECRET_TOKEN);
Create a knowledge base
- Use the
create_rag_knowledge_basemethod to create a knowledge base. This method takes the path to the PDF document and the name of the knowledge base as arguments.
# python
# create knowledge base
knowledge_base = client.create_rag_knowledge_base('sample.pdf', 'knowledge_base_name')
print(knowledge_base) # print the knowledge base details
// node.js
// create knowledge base
const knowledgeBase = await rivalzClient.createRagKnowledgeBase('sample.pdf', 'knowledge_base_name');
console.log(knowledgeBase); // print the knowledge base details
This method will return the knowledge base details as a JSON object. Which include the knowledge base id. You can use
this id later to query the knowledge base.
The embedding process may take some time depending on the size of the document. This process will be process off request you can check when the process is done by checking the status of the knowledge base.
knowledge_base = client.create_rag_knowledge_base('sample.pdf', 'knowledge_base_name')
print(knowledge_base) # you will get knowledge base id with status 'processing'
# check the status of the knowledge base
knowledge_base = client.get_knowledge_base(knowledge_base['id'])
print(knowledge_base['status']) # you will get 'ready' when the process is done
// node.js
const knowledgeBase = await rivalzClient.createRagKnowledgeBase('sample.pdf', 'knowledge_base_name');
console.log(knowledgeBase); // print the knowledge base details at this point the status will be 'processing'
// check the status of the knowledge base
const knowledgeBaseStatus = await rivalzClient.getKnowledgeBase(knowledgeBase.id);
console.log(knowledgeBaseStatus.status); // you will get 'ready' when the process is done
Full code example
- Python
# main.py
import os
from dotenv import load_dotenv
from rivalz_client.client import RivalzClient
import time
def main():
# Load environment variables from .env file
load_dotenv()
# Get the secret token from environment variables
secret_token = os.getenv('SECRET_TOKEN')
if not secret_token:
raise ValueError("SECRET_TOKEN is not set in the environment variables.")
# Initialize the RivalzClient with the secret token
client = RivalzClient(secret_token)
# create knowledge base
knowledge_base = client.create_rag_knowledge_base('sample.pdf', 'knowledge_base_name')
print(knowledge_base) # print the knowledge base details
#sleep for 5 seconds to allow the process to finish you can do this in a loop
time.sleep(5)
# check the status of the knowledge base
knowledge_base = client.get_knowledge_base(knowledge_base['id'])
print(knowledge_base['status']) # you will get 'ready' when the process is done
if __name__ == '__main__':
main()
- Node.js
// main.js
import RivalzClient from 'rivalz-client';
import dotenv from 'dotenv';
dotenv.config();
async function main() {
const rivalzClient = new RivalzClient(process.env.SECRET_TOKEN);
const knowledgeBase = await rivalzClient.createRagKnowledgeBase('sample.pdf', 'knowledge_base_name');
console.log(knowledgeBase); // print the knowledge base details
// sleep for 5 seconds to allow the process to finish you can do this in a loop
await new Promise(resolve => setTimeout(resolve, 5000));
// check the status of the knowledge base
const knowledgeBaseStatus = await rivalzClient.getKnowledgeBase(knowledgeBase.id);
}
main();
Next Steps
- Now you have successfully created your first knowledge base. You can use this knowledge base to build a Retrieval Augmented Generation (RAG) App.